Your all-in-one AI powerhouse for your
productivity
Experience ultimate productivity with our comprehensive suite of AI tools, seamlessly integrated to enhance every aspect of your workflow
Including products of renowned AI companies





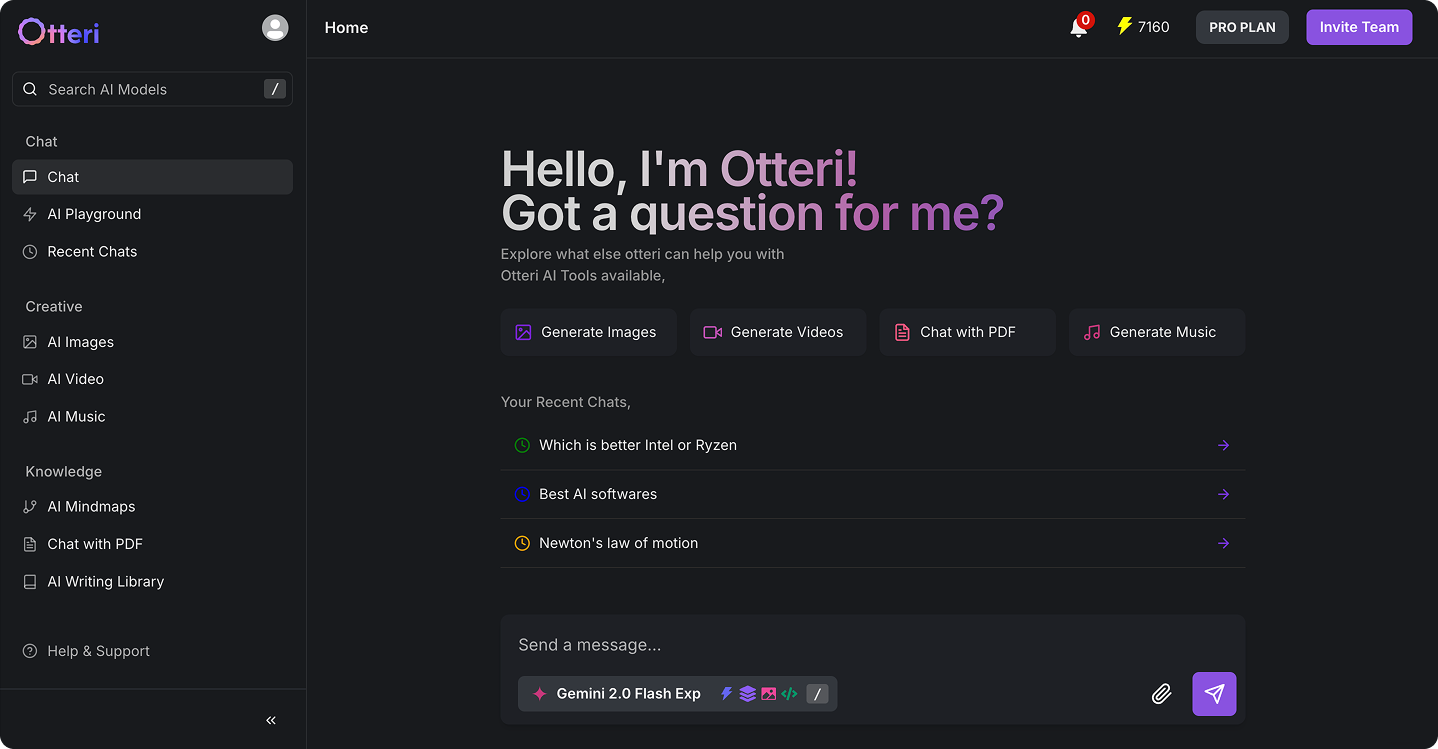
Every AI Service You Need In One Subscription!
Create high-quality text effortlessly
Otteri AI helps you generate, refine, and perfect writing in seconds—from blogs to ad copy. Enhance clarity, improve tone, and tailor content while saving time with AI-assisted ideation and formatting.


AI-powered mind maps for structured thinking
Transform scattered thoughts into clear, organized mind maps with AI. Otteri AI automates idea helping you to plan and analyze information visually. Generate dynamic, interactive mind maps with real-time AI suggestions.
Transform visuals with AI-driven creativity
Generate images, enhance videos, and automate captions in a few clicks. Whether for custom graphics or AI-enhanced content, Otteri AI simplifies the process. Create professional visuals and streamline your workflow effortlessly.

Our customers say it best.


Marcus Rodriguez
Digital Marketing Director
InnovateCorp

Emily Johnson
UX Content Strategist
DesignStudio Pro

David Kim
Social Media Manager
BrandForward

Alexandra Smith
Content Creator
Creative Labs
All AI Models in One Platform
Access Otteri AI’s complete suite of models from Grok, ChatGPT, DeepSeek, Claude, Llama, and Gemini. Tackle complex tasks, generate unique content, and enhance creativity—all in one seamless platform.

Frequently Asked Questions
Find answers to common questions about Nexobe's services and solutions
Otteri.ai is an all-in-one AI productivity platform that combines advanced text generation and refinement, AI-powered mind mapping, and creative visual tools into a single, streamlined workflow—enabling you to write, organize, and visualize ideas effortlessly.
Otteri.ai is ideal for content creators, marketers, students, educators, small business owners, and anyone seeking to enhance productivity—whether you're brainstorming ideas, drafting content, mapping concepts, or generating visuals. AI tools help reduce manual effort and accelerate creativity.
Not at all. Otteri.ai is designed for users of all levels—no coding or technical know-how required. Its intuitive interface makes it easy to generate and refine content, create mind maps, and produce visuals with just a few clicks.
Absolutely! Otteri.ai covers a full spectrum: from drafting and polishing text to generating AI visuals, mind mapping, video enhancement, captioning, and image upscaling—perfect for multimedia workflows.
User trust is important. Otteri.ai uses secure, encrypted processing to protect your content. However, as with any cloud-based solution, we advise against uploading highly sensitive or proprietary data unless you’re using enterprise-grade or on-premise options—with more advanced privacy protections.
Yes, Otteri.ai offers a free tier with basic features like text generation and simple mind mapping. Premium plans unlock advanced capabilities like visual generation, video tools, higher usage limits, and commercial usage rights.
Yes! Use it to draft blog posts, outlines, summaries, or ad copy. While Otteri.ai can help with structuring content and generating ideas, it’s best paired with your own strategy and manual editing to optimize for SEO and tone.
Simply sign up on the website to begin. You’ll have access to tutorials, prompts, and templates to ease you into generating text, mapping ideas, and creating visuals. Plus, dedicated support resources are available to guide you.
Otteri.ai works seamlessly across all platforms, including desktop and mobile, ensuring you can access it anytime, anywhere.
Try Otteri for free right away!
Boost the traffic to your website and social media accounts. online traffic into sales, and clients into advocates.